上一篇文章有提到棒球賽的事件本身,這篇開始,要提到調查的過程以及改善的策略。
雖然事件的主因看起來是很明顯的,也就是短時間內因為活動而大量湧入的使用者,對我們的伺服器發出的大量請求,最後導致我們伺服器因為承受不住而無法給出回應。 然而在調查這件事情的時候,筆者馬上面臨了第一個挑戰,因為使用者數量看起來沒有差到非常多。
請再看一次下圖, 也就是上篇文章中有提到,網站整體使用者的數量:
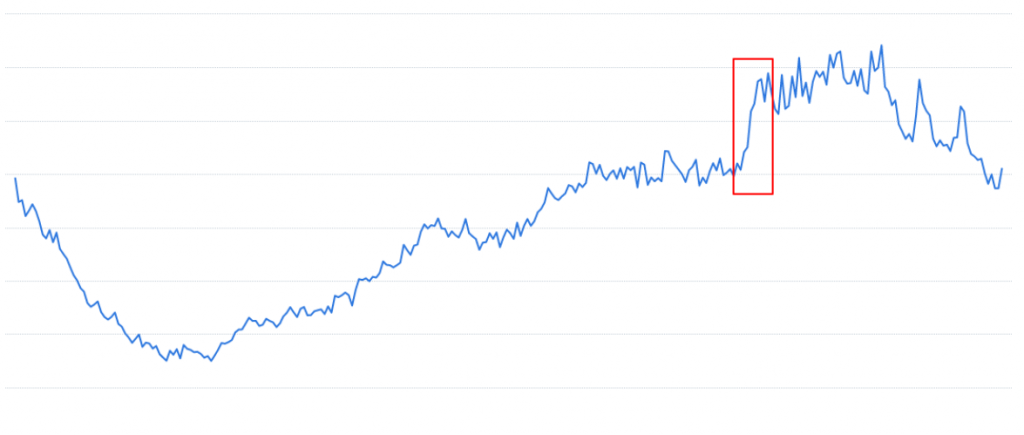
圖中紅色框框圈起來部分,雖然的確是一個陡峭的上升曲線,但與原本這個網站的使用者數量相比其實並不算多。雖然這邊不方便透漏實際的數字,但大致可以理解為,半小時內增加的使用者其實大約只有原本在線的使用者的 20-30% 而已。
因此我們第一個要解決的問題,就是為什麼數量如此稀少的使用者卻會直接導致我們網站倒站半小時呢?是因為平常我們的伺服器就已經處在接近滿載的狀況嗎? 答案是否定的,因為我們的自動擴展機制設定為CPU 50%, 因此直到流量衝進來之前,我們的後端或資料庫伺服器都是處在還非常有餘裕的狀況。
那麼,難道是因為我們的網站其實遭受到了駭客的攻擊嗎?可是駭客怎麼會這麼剛好的挑了棒球賽發生的當下發起攻擊呢?雖然我們也無法完全排除這個可能性,但既然剛好在這個時間點有大型活動,也許我們還是應該先以正常使用的角度來切入,嘗試調查具體發生的事情。
在經過一番思考後,筆者得出來的結論如下。首先,我們模擬一下,如果我們剛進入一個網站的時候會做什麼事情呢?可能會需要登入,因為要看棒球賽的關係,我們可能也會需要選擇棒球賽的頻道,因為剛進網站的關係,我們可能也會想要稍微滑一下這個網站,或是隨便看看某些我們可能感興趣的東西。
對於一個剛進網站的人來說,這些當然都是非常正常的操作。不過這每一個操作都可能對後端的伺服器發出一個或多個請求。相較於一個已經在線上待了很久的使用者而言,他可能單純只是掛在線上,或是正在觀看一個影片(還記得我們是線上影音串流平台嗎)而已。
換言之,剛進入網站的每一個使用者所發出的請求都會是原本已經在線上的使用者的好幾倍。因此我們可以合理判斷是這些剛進來的使用者的操作,導致我們伺服器承受不住。而這邊的重點在於說,我們至少可以初步判斷,大概不是受到駭客攻擊;或使用者有異常操作;或我們的程式沒有寫好之類的狀況。這對於後續的問題解決非常重要,因為如果搞錯問題本身,那可能一開始就會直接朝錯誤的方向去找解決方案。
找到成因之後,筆者接下來要釐清的問題,就是服務本身到底是壞在哪個地方?我們知道使用者發出請求,會經過前端的伺服器,後端的伺服器,到資料庫然後再回來,這整個過程裡面會經歷非常多不同的服務或資源。 一般而言,請求如果回不來,通常不是因為這一連串的服務都壞掉,而是單純某一個服務遇到了困難,因此請求或回應就卡在這個地方無法繼續。 換個說法, 筆者接下來想要找的東西,就是我們系統的瓶頸(bottleneck)。
第一個切入點就會是各個服務在事件當下的 CPU 使用狀況,而非常明顯的,資料庫伺服器看起來是 CPU 爆炸之處,因此我們這邊初步的判斷,就會是請求大概是卡在資料庫裡面出不來了。請見下一張圖:
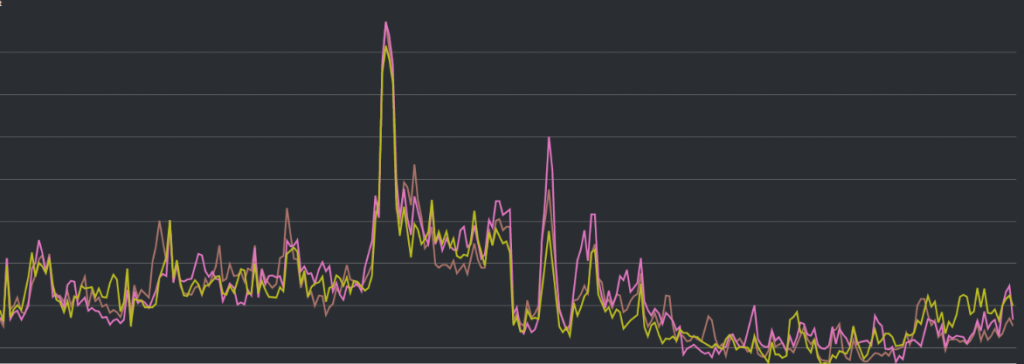
在上一篇文章一樣也有這張圖,是資料庫伺服器的 CPU 使用量以及時間的折線圖。雖然一樣沒有辦法給各位看數字,但中間那個陡峭的曲線的頂點,就是 CPU 衝到 100% 的地方。此外我們也發現在事件當下,有一些花費大量時間的 SQL query 正在佔用資料庫伺服器的資源(單一 query 長達 3 秒),如下圖:

經過進一步的調查,我們發現資料庫的自動擴展速度實在是太過緩慢,完全追不上使用者衝進來的速度。一般的後端伺服器(EC2)加開一台大約只要 5 分鐘左右的時間,但資料庫伺服器(RDS)加開一台大約需要 15 分鐘以上的時間,開完之前可能人潮早就離開了。資料庫加開會花比較長的時間其實是合理的,因為加開一台機器完之後,還要花很多時間把資料搬到機器上面。因此單純降低開機器的時間,目前看起來會比較困難。
跟據前面的討論,我們的解決方案會有以下三個方向:
在與後端工程師的討論之後,我們決定採用記憶體快取的方式來解決這個問題。在快取機制上線之前的熱門棒球賽,則都在一個小時之前左右的時間提前加開伺服器。至於熱門棒球賽的定義,則由我們的客戶來決定。 因為在這些棒球賽之前,客戶會透過推播系統來傳送訊息給使用者,而討論當下也發現,其實只有在這些熱門的棒球賽的當下,才會有使用者大量湧入的狀況。
既然我們的策略是決定要提前加開伺服器,但在這邊也有一些細節是可以討論的。資料庫伺服器因為開機速度太慢,因此我們會在球賽開打之前就直接設定一個最高等級的數字,以確保在整個棒球賽的過程中都不會有需要加開伺服器的行為發生。相對而言,後端伺服器因為加開速度較快,所以我們可以保有一些讓它自由增長的空間。
事實上,要準備評估剛好的伺服器數量極為困難。即使 在使用者數量可以預期的前提之下,我們也會因為使用者衝進來的速度,而導致要加開的伺服器數量有所不同。 因此必須老實說,最後都會是先開一個比較保守的數量,然後再根據實際的狀況慢慢觀察。這是技術上一個筆者認為相當困難的事情,也是當初花了很多時間處理的挑戰。
最後觀察呈現如下。
這張圖是資料庫伺服器隨時間的機器數量,以及CPU的使用狀況變化:
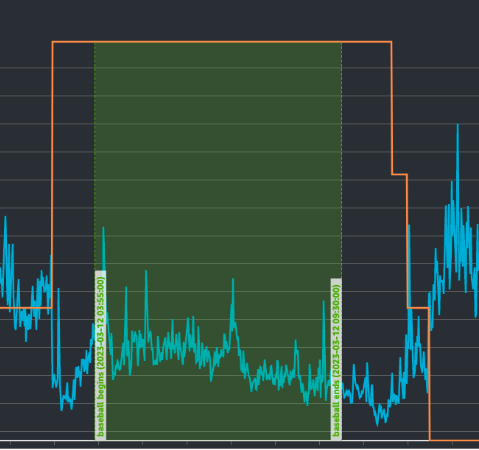
黃色的線是伺服器數量,藍色折線則是CPU的使用狀況,綠色框框的時間點是棒球賽的時間。 從這張圖中可以觀察到我們在棒球賽開打前大約一個小時的時間,就強迫資料庫伺服器的數量成長原本的2倍左右, 一直到棒球賽結束後一個小時才回歸原本的自動擴展機制。我們其實抓得相當保守(伺服器開得太多),可以看到CPU使用量在棒球賽的當下甚至是比平常還要低的。
這張圖則是後端伺服器隨時間的機器數量,以及CPU的使用狀況變化:
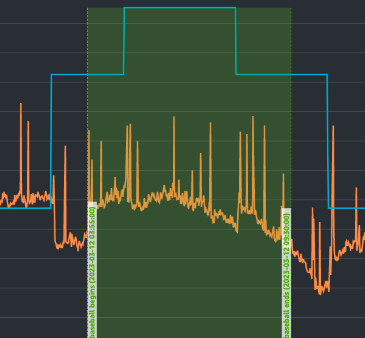
我們雖然在棒球賽開打之前,有先設定了一個最低數量,但我們沒有像資料庫伺服器那樣抓得那麼保守,因此可以看到在整個棒球賽的時間裡面,伺服器本身是有稍微增長的狀況。 也因為後端伺服器開機的速度比較快,不會影響到服務可用性,因此我們才能在這邊透過這個方式節省一些成本。
到這邊看起來算是圓滿落幕,但其實仍然留了一些值得討論的議題,會在下一篇文章再跟讀者分享。

